New user training
This page is obsolete. It is being retained for archival purposes. The current version of this page can be found at https://docs.rc.ufl.edu/training/new_user_training/
This page mirrors and expands upon the content provided in the HiPerGator Account Training in Coursera (No longer available).
Please see https://docs.rc.ufl.edu/training/new_user_training/ for the new version of the training.
Effective January 11th, 2021, this training module is required for all new account holders to obtain an account. New accounts will not be created until Coursera successfully completes the training.
Training Objectives
- Recognize the role of Research Computing, utilize HiPerGator as a research tool, and select appropriate resource allocations for analyses
- Login to HiPerGator using an ssh client
- Describe the appropriate use of the login servers and how to request resources for work beyond those limits
- Describe HiPerGator's three main storage systems and the appropriate use for each
- Use the module system for loading application environments
- Locate where to receive user support
- Identify common user mistakes and how to avoid them.
Module 1: Introduction to Research Computing and HiPerGator
HiPerGator
- About 70,000 cores

- Hundreds of GPUs
- 10 Petabytes of storage
- The HiPerGator AI cluster has

- 1,120 NVIDIA A100 GPUs
- 17,000 AMD Rome Epyc Cores


For additional information, visit our website: https://www.rc.ufl.edu/
The Cluster History page has updated information on the current and historical hardware at Research Computing.
Investor Supported
HiPerGator is heavily subsidized by the university, but we do require faculty researchers to make investments for access. Research Computing sell three main products:
- Compute: NCUs (Normalized Compute Units)

- 1 CPU core and 7.8 GB of RAM (updated Jan 2021)
- Storage:
- Blue (
/blue): High-performance storage for most data during analyses - Orange (
/orange): Intended for archival use
- Blue (
- GPUs
- Sold in units of GPU cards
- NCU investment also required to make use of GPU

Investments can either be hardware investments, lasting for 5-years or service investments lasting 3-months or longer.
- Price sheets are located here: https://www.rc.ufl.edu/get-started/price-list/
- Submit a purchase request for:
- For a full explanation of services offered by Research Computing, see: https://www.rc.ufl.edu/services/
Module 2: How to Access and Run Jobs
Cluster Components
Accessing HiPerGator
- jhub.rc.ufl.edu (requires UF Network)
- See also
 [video].
[video].
- See also
- galaxy.rc.ufl.edu
- Open on Demand: ood.rc.ufl.edu (requires UF Network)
- See also [video].
- See also
Proper use of Login Nodes
- Generally speaking, interactive work other than managing jobs and data is discouraged on the login nodes.
- Login nodes are intended for file and job management, and short-duration testing and development.

Login server acceptable use limits:
- No more than 16-cores
- No longer than 10 minutes (wall time)
- No more than 64 GB of RAM
Resources for Scheduling a Job
For use beyond what is acceptable on the login servers, you can request resources on development servers, GPUs servers, through JupyterHub, Galaxy, Graphical User Interface servers via open on demand or submit batch jobs. All of these services work with the scheduler to allocate your requested resources so that your computations run efficiently and do not impact other users.
- Development Servers
- GPU Servers
- Galaxy
- SLURM Scheduler Sample Scripts
- GUI servers, including Open on Demand
- Jupyter Hub
Scheduling a Job
- Understand the resources that your analysis will use:
- CPUs: Can your job use multiple CPU cores? Does it scale?
- Memory: How much RAM will it use? Requesting more will not make your job run faster!
- GPUs: Does your application use GPUs?
- Time: How long will it run?
- Request those resources:
- See sample job scripts
- Watch the HiPerGator: SLURM Submission Scripts training video. This video is approximately 35 minutes and includes a demonstration
- Watch the HiPerGator: SLURM Submission Scripts for MPI Jobs training video. This video is approximately 25 minutes and includes a demonstration
- Open on Demand, JupyterHub and Galaxy all have other mechanisms to request resources as SLURM needs this information to schedule your job.
- Submit the Job
- Either using
sbatchon the command line or through on of the interfaces - Once your job is submitted, SLURM will check that there are resources available in your group and schedule the job to run
- Either using
- Run
- SLURM will work through the queue and run your job
Module 3: HiPerGator Storage and the Module System for Applications
Locations for Storage
The storage systems are reviewed on this page.

Note: In the examples below, the text in angled brackets (e.g. <user>) indicates example text for user-specific information (e.g. /home/albertgator).
- Home Storage:
/home/<user>- Each user has 40GB of space
- Good for scripts, code and compiled applications
- Do not use for job input/output
- Snapshots are available for seven days
- Blue Storage:
/blue/<group>- Our highest-performance filesystem
- All input/output from jobs should go here
- Orange Storage:
/orange/<group>- Slower than /blue
- Not intended for large I/O for jobs
- Primarily for archival purposes
- Red Storage:
/red/<group>- All flash parallel filesystem primarily for HiPerGator AI
- Space allocated based on need
- Scratch filesystem with data regularly deleted
Backup and Quotas

- This page describes the tape backup options and costs.
- Orange and Blue storage quotas are at the group level and based on investment.
- See price sheets
- Submit a purchase request
- The
blue_quotaandorange_quotacommands will show your group's current quota and use. - The
home_quotacommand will show you home directory quota and use.
Directories

ls in /blue does not show the group directory for ufhpc. After a cd into the directory, and back out, it does show. This shows how the directory is automounted on access. Of course, it would be easier to just go directly without stopping in /blue first.- Directories on the Orange and Blue filesystems are automounted--they are only added when accessed.
- Your group's directory may not appear until you access it.
- Do not remove files necessary for your account to function normally, such as the ~/.ssh and /home directories.
- Remember
- Directories may not show up in an
lsof/blueor/orange- If you
cdto/blueand typels, you will likely not see your group directory. You also cannot tab-complete the path to your group's directory. However, if you add the name of the group directory (e.g.cd /blue/<group>/the directory becomes available and tab-completion functions. - Of course, there is no need to change directories one step at a time...
cd /blue/<group>, will get there in one command.
- If you
- You may need to type the path in SFTP clients or Globus for your group directory to appear
- You cannot always use tab completion in the shell
- Directories may not show up in an
Environment Modules System
- HiPerGator uses the lmod environment modules system to hide application installation complexity and make it easy to use the installed applications.
- For applications, compilers or interpreters, load the corresponding module
- More on the module system
- Basic module use
- Installed Applications
Module 4: Common Mistakes and Getting Support
Common Mistakes
- Running resource intensive applications on the login nodes is against HPG usage policy. Learn more at HPC Computation. To avoid involuntary policy violation, we recommend to run computational processes using either of the following methods:
- Submit a batch job: see Sample Slurm Scripts
- Request a development session for testing and development
- Writing to
/homeduring batch job execution - Wasting resources
- Understand CPU and memory needs of your application
- Over-requesting resources generally does not make your application run faster--it prevents other users from accessing resources.
- Blindly copying lab mate scripts
- Make sure you understand what borrowed scripts do
- Many users copy previous lab mate scripts, but do not understand the details
- This often leads to wasted resources
- Misunderstanding the group investment limits and the burst QOS
- Each group has specific limits
- Burst jobs are run as idle resources are available
- The
slurmInfocommand can show your group's investment and current use as well as HPG cluster utilization.
- The
- When using our Python environment modules, attempting to install new Python packages may not work because incompatible packages may get installed into the ~/.local folder and result in errors at run time. If you need to install packages, create a personal or project-specific Conda environment or request the addition of new packages in existing environment modules via the RC Support System.
How to get Help
See the FAQ page for these and more hints, answers, and potential pitfalls that you may want to avoid. See the Get Help page for more details. In general,
- Submit support requests via the UFRC Support System
- For problems with running jobs, provide:
- JobID number(s)
- Filesystem path(s) to job scripts and job logs
- As much detailed information as you can about your problem
- For requests to install an application, provide:
- Name of application
- URL to download the application
Additional information for students using the cluster for courses
The instructor will provide a list of students enrolled in the course
Course group names will be in the format pre1234 with the 3-letter department prefix and 4-digits course code.
- All sections of a course will typically use the same group name, so the name may be different from the specific course you are enrolled in.
- In the documentation below, substitute the generic
pre1234with your particular group name.
Students who do not have a HiPerGator Account will have one created for them Students who already have a HiPerGator Account will be added to the course group (as a secondary group)
- You can create a folder in the class's
/blue/pre1234folder with your GatorLink username - To use the resources of the class rather than your primary group, use the
--accountand--qosflags, in the submit script, in thesbatchcommand or in the boxes in the Open on Demand interface.- In your submit script, add these lines:
#SBATCH --account=pre1234
#SBATCH --qos=pre1234 - In the
sbatchcommand:sbatch --account=pre1234 --qos=pre1234 my_script.sh - Using Open on Demand:
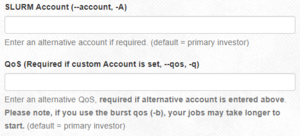
How to set account and qos options to use resources from a secondary group - JupyterHub can only use your primary group's resources and cannot be used for accessing secondary group resources. To use Jupyter using your secondary group, please use Open on Demand.
- In your submit script, add these lines:

Using your account implies agreeing to the Acceptable use policy. Students understand that no restricted data should be used on HiPerGator Classes are typically allocate 32-cores, 112GB RAM and 2TB of storage
- Instructors should keep this in mind when designing exercises and assignments
- Students should understand that these are shared resources: use them efficiently, share them fairly and know that if everyone waits until the last minute, there may not be enough resources to run all jobs.
All storage should be used for research and coursework only.
Accounts created for the class and the contents of the class /blue/pre1234 folder will be deleted at the end of the semester. Please copy anything you want to keep off of the cluster before the end of the semester.
Students should consult with their professor or TA rather than opening a support request.
- Only the professor or TA should open support requests if needed.